Introduction
- La technique du pipeline est une technique de mise en oeuvre qui permet à plusieurs instructions de se chevaucher pendant l’exécution.
- Une instruction est découpée dans un pipeline en petits morceaux appelés étage de pipeline.
- La technique du pipeline améliore le débit des instructions • La technique du pipeline améliore le débit des instructions plutôt que le temps d’exécution de chaque instruction.
- La technique du pipeline exploite le parallélisme entre instructions d’un flot séquentiel d’instructions.
1
Exemple: Opération Séquentiel de lavage ou bien du linge pipeline
4 personnes ; chacun doit :
laver, sécher, repasser, ranger lavage : 30 minutes
séchage : 40 minutes
Repassage : 30 minutes
Rangement : 20 minutes
2
Notion de PipelineA B C D
Lavage du linge en séquentiel
O30 rdre
6 PM 7 8 9 10 11 12 1 2 AM
30 40 30 20 A 40 Time 30 20 30 40 30 20 30 40 30 20 BeTâche• 8 heures pour terminer s
CD
D
C B A L S Re Ra 3
OrdreT Tâches Phase de
remplissage
Phase de déchargement
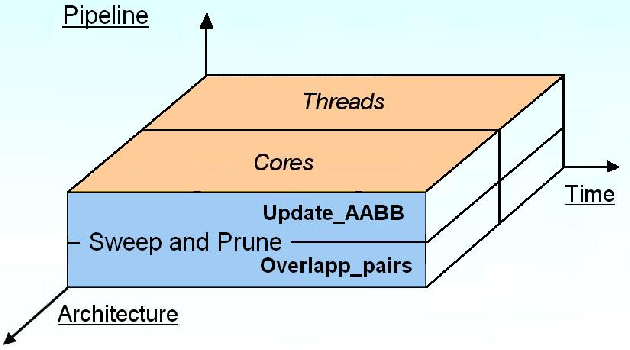
Pipeline=Toutes les ressources fonctionnent en parallèles
4
Lavage linge en pipeline
6 PM 7 8 9 10 11 Temps
A BC30 40 40 40 40 30 20
=240mn/60
- 4 heures !
30 40 30 20 L S Re Ra
CD
Rappel : diagramme d’état
IR <- Mem[PC]; PC <– PC+4;
A <- R[rs]; B<– R[rt]
BEQ/BNE
S <– A + B; S <– A or ZX; S <– A + SX; S <– A + SX; If Cond
PC < PC+SX;
R[rd] <– S;
SW M <– Mem[S]
Mem[S] <- B
3 cyc
R type I type LW
4 cyc R[rt] <– S; R[rd] <– M; 4cyc 4cyc 5 cyc
1 Approche : toutes les instructions aient même nb d’étages 5 (5 Cyc)
2 Approche : chaque type d’instruction ait son nombre d’étage 5
1 Approche de Pipeline : 5 étages 5 Etages pour Chargement (LW)
L’exécution de l’instruction se fait en 5 étapes comme suit ! 1. Lecture de l’instruction 2. Décodage et en même temps lecture des registres 3. Calcul dans l’UAL
❖ ❖ Instruction Instruction UAL UAL : : appliquer appliquer l’opération l’opération ❖ Instruction Mémoire : Calculer l’adresse ❖ Instruction de branchement : Calculer l’adresse de branchement
et évaluer la condition 4. Accès mémoire 5. Mise à jour du registre destination (pour les UAL et loads)
ou CP (pour les branchements)
6
une seule UAL et deux ADD et deux mémoires
7
Rappel :Chemin de données de monocycle
une seule UAL et une seul mémoire : solution n’est pas retenue pour insuffisance de matériels
8
Rappel :Chemin de données de multicycle
Idée: Ajouter des registres intermédiaires pour sauvegarder les informations fournies par chaque étage 9
Idée de Base : Pipeline
Pipeline : Ajout de registres intermédiaires
10
2PC
100
6R ea d ADD R1, R2, R3
re gister 1 37
Rea d re gister 21
5Re ad data 1
re Write
gister
R e gist ers
data Re ad 2 3 2MuWrite x data
Zero ALU
ALU res ult 1
Ad dre ss
R e ad data Data me mory 1
Write
1 Mux0 data
16 Sign
exte nd
11 L’instruction contient des informations qui seront utilisées bien après la lecture 104 Sub R5, R6, R7
(numéros de l’instruction. des registres, Il faut les signaux mémoriser.
de contrôle, 11
…)
Les instructions ne sont pas sauvegardées
4 Add Add re s ult
Shift
EX: Execute/ address calculation
MEM: Memory access
Num de reg Contenu reg Branchement terminé étape 4 IF: Instruction fetch ID: Instruction decode/
register file read 0WB: Write
back
Mux1Ad d
le ft 2
Addres s
Instruction
Instruction
me mory
32
0
R ea d PC
re gister 1
R e a d
R ea d
dat a 1 re gister 2Ze ro
R egiste rs Write re gister
R e a d dat a 2
Write 0 dat a
16 Sign
ext e nd
ALU
ALU Mre s ult R uD ata x
me mory
ea d da ta
Write data
1
Ad dre ss
Ces « buffers » sont utilisés non seulement pour stocker les données mais aussi les signaux de contrôle. L’écriture dans les buffers est faite à chaque fin de cycle par les signaux : FI/IDWrite, ID/ExWrite, EX/MemWrite, Mem/RbWrite
1 Mux12
Chemin de données pipeline : ajout des buffers
0Buffer pour stocker le résultat : le tapis roulant Mux1Ad d
4 Add Ad d
re s ult
S hift left 2
In str uction
me mory
IF/ID ID/EX
EX/ MEM MEM/W B
Addre ss
3 2
0
R ea d PC
re gister 1
R e a d
R ea d
dat a 1 re gister 2Ze ro
R egiste rs Write re gister
R e a d dat a 2
ALU
ALU Mre s ult uD ata x
me mory
Write 0 dat a
16 Sign
ext e nd
R ea d da ta
Write data
1
Ad dre ss
13
1 Mux
Chemin de données pipeline : ajout des buffers
0MuBuffer pour stocker le résultat : le tapis roulant x1Ad d
4 Add Ad d
re s ult
S hift left 2
In str uction
me mory
IF/ID ID/EX
EX/ MEM MEM/W B
Addre ss
3 2
0
R ea d PC
re gister 1
R e a d
R ea d
dat a 1 re gister 2Ze ro
R egiste rs Write re gister
R e a d dat a 2
ALU
ALU Mre s ult uD ata x
me mory
Write 0 dat a
16 Sign
ext e nd
R ea d da ta
Write data
1
Ad dre ss
14
1 Mux
Chemin de données pipeline : ajout des buffers
0Buffer pour stocker le résultat : le tapis roulant Mux1Ad d
4 Add Ad d
re s ult
S hift left 2
In str uction
me mory
IF/ID ID/EX
EX/ MEM MEM/W B
Addre ss
3 2
0
R ea d PC
re gister 1
R e a d
R ea d
dat a 1 re gister 2Ze ro
R egiste rs Write re gister
R e a d dat a 2
ALU
ALU Mre s ult uD ata x
me mory
Write 0 dat a
16 Sign
ext e nd
R ea d da ta
Write data
1
Ad dre ss
15
1 Mux
Chemin de données pipeline : ajout des buffers
0MuBuffer pour stocker le résultat : le tapis roulant x1Ad d
4 Add Ad d
re s ult
S hift left 2
In str uction
me mory
IF/ID ID/EX
EX/ MEM MEM/W B
Addre ss
3 2
0
ER
NHA/MMY Pipeline
Based on UCB
Page : 16
Contrôle
ERMEX
ERM
ERM
EI/DI DI/EX EX/MEM MEM/ER
Processeur avec pipeline
Remarques sur le traitement en pipeline
- Traitement en pipeline n ’améliore pas le temps de chaque tâche, mais le débit des opérations
- Tâches multiples en parallèles avec ressources différentes
- Débit de pipeline est limité par l ’étage le plus lent
Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5
Ifetch Reg/Dec Exec Mem Wr
15ns 5ns 10ns 15ns 5ns
IRDE Mem Wr 30ns 15ns 5ns
CLK=15ns
CLK=30ns
17
Remarques sur le traitement en pipeline
- Longueur non-équilibrée réduit le gain de temps
- Temps pour « remplir » et « décharger » pipeline pipeline réduit réduit le le gain gain de de temps temps
- Gain de temps = Nombre d ’étages (un μp à k étages est k fois plus rapide qu’un μp simple)
18
Représentation d’exécution en pipeline à 5 étages
Temps
IFetch Dcd Exec Mem WB
IFetch Dcd Exec Mem WB
IFetch Dcd Exec Mem WB
IFetch IFetch Dcd Dcd Exec Exec Mem Mem WB WB
IFetch Dcd Exec Mem WB
Déroulement du programme
IFetch Dcd Exec Mem WB Phase de déchargement: sauvegarde des résultats19
Comparaison: 1-Cycle, Multi-Cycle, Pipeline
Clk
Cycle 1 Cycle 2 Clk
Implémentation 1-Cycle:
LW SW Perte
Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7 Cycle 8 Cycle 9 Cycle 10
Implémentation Multi-Cycle:
LW SW
Ifetch Reg Exec Mem Wr
Implementation Pipeline:
LW Ifetch Reg Exec Mem Wr
SW
Ifetch Reg Exec Mem Wr R-type
Ifetch Reg Exec Mem
Ifetch
R-type
Ifetch Reg Exec Mem Wr 20
Pourquoi le pipeline?
Ifetch Reg Exec Mem Wr 10 +7 +10 +10 +7
- Exécution de 100 instructions
- Machine 1-Cycle (10+7+10+10+7)
– 44 ns/cycle x 1 CPI x 100 inst = 4400 ns
- Machine Multi-Cycle
– 10 ns/cycle x 4.1 CPI (mixte d ’instructions) x 100 inst = 4100 ns
- Machine en Pipeline
– 10 ns/cycle x (1 CPI x 100 inst + 4 cycles remplissage) = 1040 ns
CPI=Cycle Par Instruction 21
OrdreI
nstructions
Temps (cycles)
Inst 0
Inst 1
Im Reg Dm Reg
Inst 1
Im Reg Dm Reg
Inst 2 Inst 3
Inst 4
Ressources Disponibles!
Im Reg Dm Reg
Im Reg Dm Reg
Im Reg Dm Reg
Im Reg Dm Reg
22
Problèmes avec les Pipelines?
- Types d ’aléas (« hazards ») :
– Aléas de contrôle: prendre décision avant d’évaluer la
condition
- instruction de saut conditionnel
– Aléas de données: utilisation d’une donnée avant qu’elle
soit prête soit prête
- instruction dépend des résultats d ’une instruction antérieure encore dans le pipeline . Aléas de structure: utilisation d’une même ressource
plusieurs fois en même temps – Aléas résolus par suspension (attente) – Aléas résolus par prédiction (correcteur) – Aléas résolus par renvoi (envoyer l’information d’un étage à
un autre)
Mémoire : Aléas de structure
Temps
Load
Mem Reg Mem Reg
Instr 1
Mem Reg Mem Reg
Instr 2
Mem Reg Mem Reg
Instr 3
Reg Mem Reg
Instr 4
Mem Reg Mem Reg
Mem
Mem
NHA/MMY Détection Pipeline
facile ! Solution limite la performance.
Based on UCB
Page : 24
Aléas de contrôle
Si la condition est vérifiée le problème se situe au niveau de l’éxcétion des instructions and, or et sub qui viennent de commencer à être excéuter : perte de temps
06: add r8,r1,r9
14: and r2,r3,r5
18: or r6,r1,r7
22: sub r8,r1,r9
36: xor r10,r1,r11 37: ori r2,r1,20 38: add r9,r3,r5 10: beq r1,r3,36
Ifetch Reg DMem Reg
14: and r2,r3,r5 Ifetch Ifetch Reg Reg DMem DMem Reg Reg
Ifetch Reg DMem Reg
Ifetch Reg DMem Reg
Ifetch Reg DMem Reg
25 Page : 25
- 1prémiére Solution: Suspension
Suspension: possibilité de prendre la décision après 2 cycles par ajout de hardwares : attendre jusqu’à ce que la décision puisse être prise Add
Beq
And
Mem Reg Mem Reg
Bulle Bulle
Mem Reg Mem Reg Stall
Suspension
26
Temp (en cycles)
Add Mem Reg Mem Reg
or
sub
Mem Reg Mem Reg
Mem Reg Mem Reg
Mem Reg Mem Reg xor
27 Pas de cycle perdu
2éme Solution: Prédiction
- a) Prédiction: Bonne (pas de saut : ZF=0)Temps (en cycles)
Add
Beq
Mem Reg Mem Reg
*: condition n’est pas
*: condition n’est pas
Mem Reg *
Mem Reg
Mem Reg
vérifiée
vérifiée
And
Mem Reg Mem Reg
2éme Solution: Prédiction
Beq NOP And
or
Mem Reg Mem Reg
Xor
2 cycles perdues
Mem Reg Mem Reg
37: ori
Impact: 1 cycles / instruction saut si prédiction est correcte zf=1, 2 cycle en cas d ’erreur zf=0 Mem Reg Mem Reg (condition correcte = saut =50%)
28
Prédiction: est fausse (il ya un saut ZF=1)Temps (en cycles)
Add Mem Reg Mem Reg
Mem Reg *
Mem Reg
Mem Reg Mem Reg
*: condition vérifiée
Aléas de donnée
- Problème est la dépendances en arrière de la donnée r1
Temps (en cycles)
add r1,r2,r3
sub r4,r1,r3
F ID/R EX ME ER Im
Reg Dm Reg
Im Reg Dm Reg
and r6,r1,r7
or r8,r1,r9
xor r10,r1,r11
Im Reg Dm Reg
Im Reg Dm Reg
Im Reg Dm Reg
29
Solution Aléas de Données:
- Solution est de “Renvoyer” résultat d ’une étape vers une autre
Temps (en cycles)
add r1,r2,r3
sub r4,r1,r3
IF ID/RF EX MEM WB Im Reg Dm Reg
Im Reg Dm Reg
and r6,r1,r7
or r8,r1,r9
xor r10,r1,r11
Im Reg Dm Reg
Im Reg Dm Reg
Im Reg Dm Reg
30
Aléas de données: cas Load
- Dépendances en arrière
Temps (en cycles)
lw r1,0(r2)
sub r4,r1,r3
ID/RF Probléme IEX MEM WB F Im Reg Dm Reg
Im Reg Dm Regsolution Im Reg
Bulle Dm Reg Suspension
- Renvoi impossible
- Suspension est la seule solution
31
Rappel : diagramme d’état
IR <- Mem[PC]; PC <– PC+4;
A <- R[rs]; B<– R[rt]
BEQ/BNE
S <– A + B; S <– A or ZX; S <– A + SX; S <– A + SX; If Cond
PC < PC+SX;
R[rd] <– S;
SW M <– Mem[S]
Mem[S] <- B
3 cyc
R type I type LW
4 cyc R[rt] <– S; R[rd] <– M; 4cyc 4cyc 5 cyc
1 Approche : toutes les instructions aient même nb d’étages 5 (5 Cyc)
2 Approche : chaque type d’instruction ait son nombre d’étage
32
Problème avec Pipeline à n étages suivant type d’instruction
-Aléas de structure: utilisation d’une même ressource plusieurs fois en même temps temps
-Résolution: par suspension (attente) ou ajout d’étape
33
Rappel : Instruction de chargement LW
Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7
Clock
1er lw Ifetch Reg/Dec Exec Mem Wr • Les 5 unités indépendantes du chemin données pipeline:
– Mémoire Instruction pour étape Ifetch – – Port Port lecture lecture du du Banc Banc Registres Registres (bus (bus A A et et bus bus B) B) pour pour étape étape Reg/Dec – ALU pour étape Exec – Mémoire données pour étape Mem – Port lecture du Banc Registres port écriture (bus W) à l ’
étape Wr
34
Rappel : Instruction type-R
- Ifetch
– Lecture de l ’instruction de mémoire instructions
- Reg/Dec
Cycle 1 Cycle 2 Cycle 3 Cycle 4
R-type Ifetch Reg/Dec Exec Wr • Reg/Dec
– Lecture registres et décodage de l ’instruction
- Exec
– Opération ALU sur les deux registres
- Wr– Ecriture résultat dans un registre
35
Aléas de structure
Pipeline avec type-R et LW
Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7 Cycle 8 Cycle 9
Clock
R-type
Ifetch Reg/Dec Exec Wr Problème!
R-type
Ifetch Reg/Dec Exec Wr LW
LW
Ifetch Ifetch Reg/Dec Reg/Dec Exec Exec Mem Mem Wr Wr R-type Ifetch Reg/Dec Exec Wr R-type Ifetch Reg/Dec Exec Wr • Un conflit (aléas de structure ou
matériel):
– Deux instructions :écriture dans le Banc registre en
Deux Solutions possibles: -suspendre même temps! – Un seul port écriture
-ralentir
36
Solution 1: Suspension du pipeline
Clock
Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7 Cycle 8 Cycle 9
Ifetch Reg/Dec Exec Wr
Load
Ifetch Reg/Dec Exec Mem Wr R-type
Ifetch Reg/Dec Exec Wr R-type Ifetch Reg/Dec Bulle
Exec Wr R-type
Ifetch Pipeline Reg/Dec Exec Wr • Insertion de “bulle” pour élimination de conflit:
– Logique de contrôle compliquée. – Pas de démarrage de nouvelle instruction.
- Pas de démarrage d’instruction en Cycle 6!
Ifetch Reg/Dec Exec
37
Solution 2: Ralentir l’instruction type-R
– Écriture dans le banc registre se fait au cycle 5 au lieu de 4 – NOP (pas d’opération) pour étape Mem
insertion
1 2 3 4 5 R-type Ifetch Reg/Dec Exec Mem Wr Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7 Cycle 8 Cycle 9
Clock
R-type
Ifetch Reg/Dec Exec Mem Wr R-type Ifetch Reg/Dec Exec
Mem Wr Load
Ifetch Reg/Dec Exec Mem Wr R-type Ifetch Reg/Dec Exec Mem Wr R-type Ifetch Reg/Dec Exec Mem Wr Chargement de pipeline 38
Solution : Modification Chemin&Contrôle
IR <- Mem[PC]; PC <– PC+4;
A <- R[rs]; B<– R[rt]
S <– A + B; S <– A or ZX; S <– A + SX;
S <– A + SX;
M <– Mem[S]
Mem[S] <- B
if Cond PC < PC+SX;
M <– S M <– S
Beq/Bne M <– S
M <– S
M <– Mem[S] Mem[S] <- B R[rd] <– M;
R[rt] <– M; R[rd] <– M; R type I type Load
AB
Sw
S M
D
39
Solution pour instruction SW
Cycle 1 Cycle 2 Cycle 3 Cycle 4
Ifetch Reg/Dec Exec Mem SW Wr
NOP (pas d’opération) pour étape WR
40
Solution pour Beq
Cycle 1 Cycle 2 Cycle 3 Cycle 4
Ifetch Reg/Dec Exec Mem Beq Wr
NOP (pas d’opération) pour étape Mem et WR
Conclusion : On converge vers utilisation de Pipeline à 5 étages
41
Exemple
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
28 ori r8, r9, 17 28 ori r8, r9, 17
32 add r10, r11, r12
…100 and r13, r14, 15
42
n
n n n
Mem Ctrl
rs rt
Exec Ctrl
WB Ctrl
WB Ctrl
Fetch 10
A S
M
B
10 lw r1, r2(35)
D
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
…100 and r13, r14, 15
43
rs rt
Fetch 14, Decode 10 n
n n
Exec Ctrl
Mem Ctrl
A S
WB Ctrl
M
B
10 lw r1, r2(35)
D
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
…100 and r13, r14, 15
44
Fetch 20, Decode 14, Exec 10
n n
Exec Ctrl
A S
Mem Ctrl
WB Ctrl
2 rt
M
B
10 lw r1, r2(35) D
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
…100 and r13, r14, 15
45
Fetch 24, Decode 20, Exec 14, Mem 10
A
n
Exec Ctrl
Mem Ctrl
WB Ctrl
4 5
M
B
lw r1, r2(35) D
addI r2, r2, 3
sub r3, r4, r5
beq r6, r7, 100
ori r8, r9, 17
add r10, r11, r12
…100 and r13, r14, 15
télécharger gratuitement cours de La technique du pipeline