Partie 1: Planification de l’extraction des données
La plupart des solutions d’entreposage de données utilisent un processus ETL incrémentiel pour actualiser l’entrepôt de données avec de nouveaux et données modifiées des systèmes sources. La mise en œuvre d’un processus ETL incrémental efficace présente un certain nombre de défis, pour lesquels des conceptions de solutions communes ont été identifiées. En comprenant certaines des clés caractéristiques d’un processus ETL incrémentiel,
vous pouvez concevoir une solution d’actualisation de l’entrepôt de données efficace qui répond à vos besoins d’analyse et de reporting tout en maximisant les performances et l’efficacité des ressources.
Objectifs de la leçon
Après avoir terminé cette leçon, vous serez en mesure de:
o Décrivez un scénario d’actualisation typique de l’entrepôt de données.
o Décrire les considérations relatives à la mise en œuvre d’un processus ETL incrémentiel.
o Décrire les architectures ETL courantes.
o Planifier les fenêtres d’extraction de données.
o Planifier les transformations
Présentation des cycles de chargement de l’entrepôt de données
- Extraire les modifications de la source de données
- Actualiser l’entrepôt de données en fonction des modifications
Une solution typique d’entreposage de données comprend une actualisation régulière des données dans l’entrepôt de données pour refléter les nouvelles et des données modifiées dans les systèmes sources sur lesquels elles sont basées. Pour chaque cycle de charge, les données sont extraites du systèmes source, généralement dans une zone de transit, puis chargés dans l’entrepôt de données. La fréquence des le processus d’actualisation dépend de la mise à jour des données analytiques et de rapport dans l’entrepôt de données pour être.
Dans certains cas, vous pouvez choisir d’implémenter un cycle d’actualisation différent pour chaque groupe de données associées sources.
Dans de rares cas, il peut être approprié de remplacer les données de l’entrepôt de données par des données fraîches provenant des sources de données
pendant chaque cycle de charge. Cependant, une approche plus courante consiste à utiliser un processus ETL incrémentiel pour extraire uniquement les lignes qui ont été insérées ou modifiées dans les systèmes source. Les lignes sont ensuite insérées ou mises à jour dans le entrepôt de données pour refléter les données extraites. Cela réduit le volume de données transférées, minimisant le effet du processus ETL sur la bande passante du réseau et les ressources de traitement.
Considérations relatives à l’ETL incrémentiel
Lors de la planification d’un processus ETL incrémentiel, plusieurs facteurs doivent être pris en compte:
Modifications des données à suivre
L’une des principales considérations pour la planification d’un processus ETL incrémentiel est d’identifier les types de données
les modifications que vous devez suivre dans les systèmes source. Plus précisément, vous devriez envisager les types suivants de modifications :
• Inserts – par exemple, de nouvelles transactions de vente ou de nouveaux enregistrements de clients.
• Mises à jour – par exemple, un changement de numéro de téléphone ou d’adresse d’un client.
• Suppression – par exemple, la suppression d’un article abandonné d’un catalogue de produits.
La plupart des solutions d’entreposage de données incluent des enregistrements insérés et mis à jour dans les cycles d’actualisation. Cependant, vous devez donner attention particulière aux enregistrements supprimés, car la propagation des suppressions vers l’entrepôt de données entraîne perte de données de rapport historiques.
Ordre de chargement
Un entrepôt de données peut inclure des dépendances entre les tables. Par exemple, les lignes d’une table de faits en général inclure des références de clé étrangère aux lignes dans les tables de dimension, et certaines tables de dimension incluent une clé étrangère références aux tables de sous-dimensions. Pour cette raison, vous devez généralement concevoir votre processus ETL incrémentiel
pour charger d’abord les tables de sous-dimensions, puis les tables de dimension et enfin les tables de faits. Si ce n’est pas possible, vous pouvez charger les membres inférés en tant qu’enregistrements d’espace réservé minimal pour les membres de dimension référencés par d’autres tables et qui seront chargées ultérieurement.
Remarque:
les membres inférés sont normalement utilisés pour créer un enregistrement d’espace réservé pour une dimension manquante membre référencé par un dossier de faits. Par exemple, les données à charger dans une table de faits pour les commandes client peuvent inclure une référence à un produit pour lequel aucun enregistrement de dimension n’a encore été chargé. Dans ce cas, vous pouvez créer un membre inféré pour le produit qui contient les valeurs de clé requises mais des colonnes nulles pour toutes les autres les attributs. Vous pouvez ensuite mettre à jour l’enregistrement de membre déduit lors d’un chargement ultérieur de données produit.
Clés de dimension
Les clés utilisées pour identifier les lignes dans les tables de dimension sont généralement indépendantes des clés métier utilisées dans systèmes source, et sont appelées clés de substitution. Lors du chargement de données dans un entrepôt de données, vous devez considérez comment vous allez identifier la valeur de clé de dimension appropriée à utiliser dans les scénarios suivants:
• Déterminer si un enregistrement intermédiaire représente ou non un nouveau membre de dimension ou une mise à jour d’un
existant, et s’il s’agit d’une mise à jour, appliquer la mise à jour à l’enregistrement de dimension approprié.
• Détermination des valeurs de clé étrangère appropriées à utiliser dans une table de faits faisant référence à une table de dimension,
ou dans une table de dimension faisant référence à une table de sous-dimensions.
Dans de nombreuses conceptions d’entrepôt de données, la clé métier source de chaque membre de dimension est conservée en tant que
clé alternative dans l’entrepôt de données, et peut donc être utilisée pour rechercher la clé de dimension correspondante.
Dans d’autres cas, les membres de dimension doivent être trouvés en faisant correspondre une combinaison unique de plusieurs colonnes.
Mise à jour des membres de dimension
Lors de l’actualisation des tables de dimension, vous devez déterminer si les modifications apportées aux attributs de dimension individuels
ont un effet significatif sur les rapports et analyses historiques. Les attributs de dimension peuvent être classés comme l’un des trois types:
• Fixe – la valeur d’attribut ne peut pas être modifiée. Par exemple, vous pouvez appliquer une règle qui empêche
modifie un nom de produit après son chargement dans la table de dimension.
• Changement – la valeur des attributs peut changer sans affecter l’historique des rapports et des analyses. Pour
Par exemple, le numéro de téléphone d’un client peut changer, mais il est peu probable qu’une activité historique
les rapports ou les analyses regrouperont les mesures par numéro de téléphone. Le changement peut donc être
effectuée sans qu’il soit nécessaire de conserver l’ancien numéro de téléphone.
• Historique – la valeur d’attribut peut changer, mais la valeur précédente doit être conservée pour l’historique
rapports et analyses. Par exemple, un client peut déménager d’Édimbourg à New York, mais
les rapports et l’analyse doivent associer toutes les ventes effectuées à ce client avant le déménagement avec
Edimbourg et toutes les ventes après le déménagement avec New York
Mise à jour des enregistrements de faits
Lors de l’actualisation de l’entrepôt de données, vous devez déterminer si vous autorisez les mises à jour des enregistrements de faits.
Souvent, la conception de votre entrepôt de données ne contiendra que des enregistrements de faits complets, donc aucun enregistrement incomplet ne sera chargé. Cependant, dans certains cas, vous souhaiterez peut-être inclure un enregistrement de faits incomplet dans l’entrepôt de données
qui sera mis à jour lors d’un cycle d’actualisation ultérieur.
Par exemple, vous pouvez choisir d’inclure un enregistrement de faits pour une commande client où la vente est terminée, mais l’article n’a pas encore été livré. Si l’enregistrement comprend une colonne pour la date de livraison, vous pouvez stocker initialement une valeur nulle dans cette colonne, puis mettre à jour l’enregistrement lors d’une actualisation ultérieure une fois la commande été livré.
Alors que certains professionnels de l’entreposage de données autorisent les mises à jour de l’enregistrement existant dans la table de faits, d’autres les praticiens préfèrent soutenir les changements en supprimant l’enregistrement de faits existant et en en insérant un nouveau. Dans la plupart cas, l’opération de suppression est en fait une suppression logique qui est réalisée en définissant une valeur de bit sur une colonne qui indique si l’enregistrement est actif ou non, plutôt que de supprimer réellement l’enregistrement de la table
Architectures de flux de données ETL courantes
Fondamentalement, ETL concerne le flux de données des systèmes sources vers l’entrepôt de données. Le flux de données.
Le processus peut être effectué directement de la source à la cible, ou par étapes. Facteurs qui affectent le choix des données
l’architecture de flux comprend:
• Le nombre de sources de données.
• Le volume de données à transférer.
• La complexité des opérations de validation et de transformation à appliquer aux données.
• À quelle fréquence les données sont générées dans les systèmes source et combien de temps elles sont conservées.
• Moments appropriés pour extraire les données sources tout en minimisant l’impact sur les performances des utilisateurs.
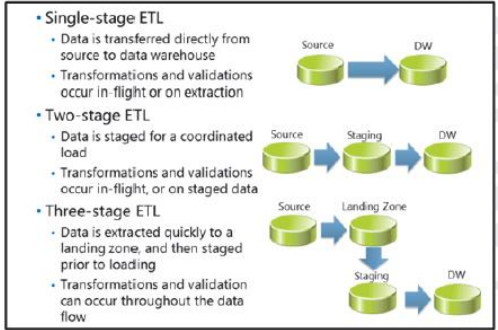
ETL à un étage
Dans une très petite solution de Business Intelligence (BI) avec peu de sources de données et des exigences simples, cela peut être possible de copier des données des sources de données vers l’entrepôt de données en un seul flux de données. Validation des données de base (comme la vérification des champs NULL ou des plages de valeurs spécifiques) et des transformations (comme la concaténation plusieurs champs dans un seul champ, ou la recherche d’une valeur à partir d’une clé) peut être effectuée lors de l’extraction (par exemple, dans l’instruction Transact-SQL utilisée pour récupérer des données à partir d’une base de données source) ou en cours (pour
exemple, en utilisant des composants de transformation dans une tâche de flux de données SSIS).
ETL à deux étages
Dans de nombreux cas, une solution ETL en une seule étape ne convient pas en raison de la complexité ou du volume des données transféré. De plus, si plusieurs sources de données sont utilisées, il est courant de synchroniser les charges dans les données entrepôt pour assurer la cohérence et l’intégrité des données factuelles et dimensionnelles provenant de différentes sources, et pour minimiser l’impact sur les performances des opérations de chargement sur l’activité de l’entrepôt de données. Si les données ne sont pas prêtes à extraire de tous les systèmes en même temps, ou si certaines sources ne sont disponibles qu’à des moments précis alors que d’autres
ne sont pas disponibles, une approche courante consiste à organiser les données dans un emplacement intermédiaire avant de les charger dans les données entrepôt.
En règle générale, la structure des données dans la zone intermédiaire est similaire à celle des tables source, ce qui minimise les complexité et durée des requêtes d’extraction dans les systèmes source. Lorsque toutes les données sources sont mises en scène, elles peuvent alors être conforme au schéma de l’entrepôt de données pendant l’opération de chargement, soit comme il est extrait du les tables intermédiaires ou pendant le flux de données vers l’entrepôt de données. Le transfert des données fournit également un point de récupération pour les échecs de chargement de données et vous permet de conserver les données extraites à des fins d’audit et de vérification.
ETL à trois étages
Une architecture de flux de données en deux étapes peut réduire la surcharge d’extraction et les systèmes source,
charge coordonnée de données provenant de sources multiples. Cependant, effectuer la validation et les transformations pendant le flux de données dans l’entrepôt de données peut affecter les performances de charge et entraîner un impact négatif de la charge activité d’entrepôt de données. Lorsque de gros volumes de données doivent être chargés dans l’entrepôt de données, il est important pour minimiser les temps de chargement en préparant autant que possible les données avant d’effectuer l’opération.
Pour les solutions BI qui impliquent le chargement de gros volumes de données, un processus ETL en trois étapes est recommandé. Dans cette architecture de flux de données, les données sont initialement extraites dans des tables qui correspondent étroitement au système source schémas, souvent appelés «zone d’atterrissage». À partir de là, les données sont validées et transformées telles quelles chargé dans des tables intermédiaires qui ressemblent davantage aux tables de l’entrepôt de données cible. Finalement, le les données conformes et validées peuvent être chargées dans les tables de l’entrepôt de données.
Planification des fenêtres d’extraction
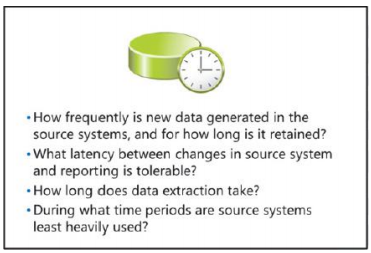
Pour vous aider à déterminer quand exécuter le processus d’extraction de données, tenez compte des questions suivantes:
À quelle fréquence les nouvelles données sont-elles générées dans les systèmes sources et pendant combien de temps retenu?
Certaines applications métier ne génèrent que quelques transactions par jour et stockent les détails en permanence. D’autres génèrent des flux de données transitoires qui doivent être capturés en temps réel. Le volume des changements et l’intervalle de stockage des données sources déterminera la fréquence d’extraction requise pour soutenir l’entreprise exigences.
Quelle latence entre les changements dans les systèmes sources et les rapports est tolérable?
Un autre facteur dans la planification des délais d’extraction des données est la nécessité de maintenir l’entrepôt de données date avec les changements dans les systèmes source. Si les rapports en temps réel (ou quasiment en temps réel) doivent être pris en charge, les données doit être extrait et chargé dans l’entrepôt de données dès que possible après chaque modification. Alternativement, si tous les rapports et analyses sont historiques, vous pourrez peut-être laisser une période de temps significative (par exemple, une mois) entre les chargements de l’entrepôt de données. Cependant, notez que vous n’avez pas besoin de faire correspondre les extractions de données une à une avec les charges de données. Si moins de frais généraux sont créés dans la source de données par une extraction nocturne de la journée changements qu’une extraction mensuelle, vous pouvez choisir de mettre en scène les données tous les soirs, puis de les charger dans les données entrepôt en une seule opération à la fin du mois.
Combien de temps dure l’extraction des données?
Effectuez un test d’extraction et notez le temps nécessaire pour extraire un nombre spécifique de lignes. Ensuite, en fonction de la façon dont de nombreuses lignes nouvelles et modifiées sont créées au cours d’une période donnée, estimez le temps qu’une extraction prendrait si effectué toutes les heures, tous les jours, toutes les semaines ou à tout autre intervalle qui a du sens, en fonction de vos réponses au premier deux questions.
Pendant quelles périodes les systèmes sources sont-ils les moins utilisés?
Certaines sources de données peuvent être disponibles uniquement pendant des périodes spécifiques, et d’autres peuvent être trop utilisées pendant les heures de bureau pour prendre en charge les frais générau supplémentaires d’un processus d’extraction. Vous devez travailler en étroite collaboration avec les administrateurs et les utilisateurs des sources de données pour identifier les périodes idéales d’extraction de données pour
chaque source.
Après avoir examiné ces questions pour tous les systèmes source, vous pouvez commencer à planifier des fenêtres d’extraction pour Les données. Notez qu’il est courant d’avoir plusieurs sources avec des fenêtres d’extraction différentes, de sorte que le temps écoulé le temps de mise en scène de toutes les données peut prendre plusieurs heures, voire plusieurs jours.
Planification des transformations
Lors de la planification d’une solution ETL, vous devez prendre en compte les transformations à appliquer aux données à le valider et le rendre conforme aux schémas de la table cible.
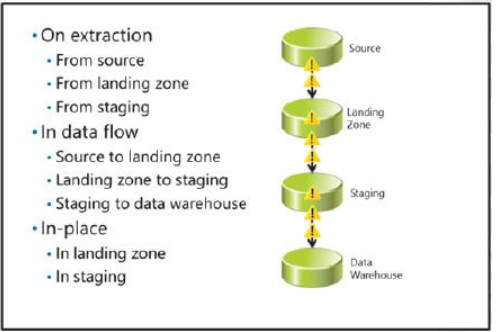
Où effectuer des transformations
Une considération pour les transformations est de savoir où elles devraient être appliquées pendant le processus ETL
Effectuer des transformations lors de l’extraction
Si les sources de données le prennent en charge, vous pouvez effectuer des transformations dans les requêtes utilisées pour extraire les données. Pour exemple, dans une source de données SQL Server, vous pouvez utiliser des jointures, des expressions ISNULL, CAST et CONVERT expressions et expressions de concaténation dans la requête SELECT utilisée pour extraire les données. Dans une entreprise Solution BI, cette technique peut être utilisée lors des extractions suivantes:
• Extraction du système source.
• Extraction de la zone d’atterrissage.
• Extraction de la zone de rassemblement.
Effectuer des transformations dans le flux de données
Vous pouvez utiliser les transformations de flux de données SSIS pour transformer les données pendant le flux de données. Par exemple, vous pouvez utilisez des recherches, des transformations de colonnes dérivées et des scripts personnalisés pour valider et modifier les lignes d’un flux de données.
Vous pouvez également utiliser des transformations de fusion et de fractionnement pour combiner ou créer plusieurs chemins de flux de données. Dans un
solution BI d’entreprise, cette technique peut être utilisée lors des flux de données suivants:
• Source vers la zone d’atterrissage.
• Zone d’atterrissage à l’étape.
• Mise en scène vers l’entrepôt de données.
Effectuer des transformations sur place
Dans certains cas, il peut être judicieux de transférer les données des sources dans une ou plusieurs tables de base de données, puis
effectuez des opérations UPDATE pour modifier les données sur place avant la phase suivante du flux de données ETL.
Par exemple, vous pouvez extraire les données d’une source et les mettre en scène, puis mettre à jour les valeurs codées en fonction de
les données d’une autre source extraites lors d’une fenêtre d’extraction ultérieure. Dans une solution BI d’entreprise, ce
technique peut être utilisée dans les endroits suivants:
• Tables de zones d’atterrissage.
• Tables de transit.
Lignes directrices pour choisir où effectuer les transformations
Bien qu’il n’y ait pas de place correcte dans le flux de données pour effectuer des transformations, tenez compte des éléments suivants
directives pour concevoir vos solutions:
• Minimisez la charge de travail d’extraction sur les systèmes source. Cela vous permet d’extraire les données dans le
temps le plus court possible avec un effet négatif minimal sur les processus métier et les applications utilisant le
la source de données.
• Effectuer les validations et transformations du flux de données dès que possible. Cela vous permet de
supprimer ou rediriger les lignes non valides et les colonnes inutiles au début du processus d’extraction, ce qui réduit
la quantité de données transférées sur le réseau.
• Réduisez le temps de chargement des tables de l’entrepôt de données. Cela vous permet d’obtenir les nouvelles données
mise en production dès que possible et effectuer le chargement avec un effet négatif minimal sur les données utilisateurs de l’entrepôt.
Comment effectuer des transformations
Vous pouvez utiliser des instructions Transact-SQL pour transformer ou valider des colonnes pendant l’extraction ou sur place.
Vous pouvez également utiliser des transformations de flux de données SSIS pour modifier les données pendant le flux de données. le Le tableau suivant répertorie certains scénarios de validation et de transformation typiques, ainsi que des informations sur la pour utiliser Transact-SQL ou des transformations de flux de données pour implémenter une solution.
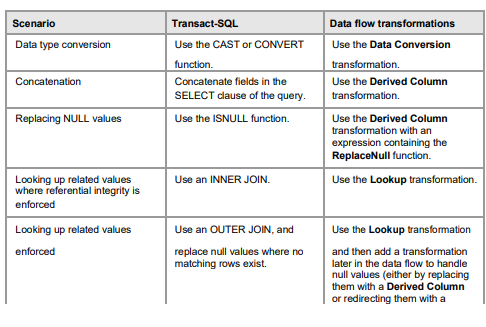
Remarque: certaines personnes qui ne sont pas familiarisées avec SSIS font l’hypothèse erronée que le flux de données traite les lignes de manière séquentielle et que les transformations de flux de données sont intrinsèquement plus lentes que celles basées sur des ensembles transformations effectuées avec Transact-SQL. Cependant, le pipeline SSIS effectue des opérations basées sur des ensembles sur mise en mémoire tampon de lots de lignes, et est conçue pour fournir une transformation haute performance dans les flux de données
Documenter les flux de données
Une partie importante de la conception d’une solution ETL consiste à documenter les flux de données que vous devez implémenter. le les diagrammes et les notes qui documentent vos flux de données sont communément appelés «source-cible» documentation, qui commence généralement par un simple diagramme de haut niveau pour chaque table de l’entrepôt de données. Le diagramme montre les tables source dont proviennent les champs de la table de l’entrepôt de données et la validation et les transformations qui doivent être appliquées pendant le flux de données.
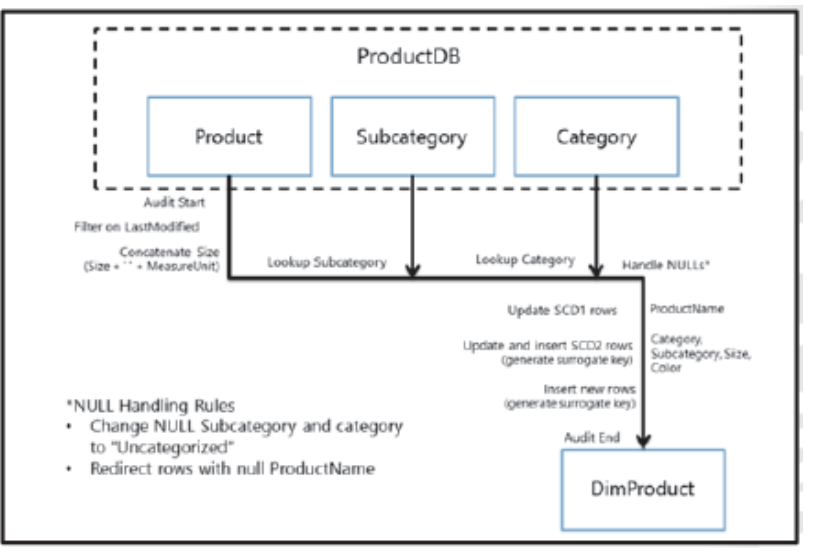
En règle générale, utilisez une approche cohérente de création de diagrammes pour chaque tableau et incluez autant de détails sur règles de validation, transformations et problèmes potentiels comme vous le pouvez. Il est courant pour ces diagrammes de haut niveau.
pour commencer simple et être affiné à mesure que la conception ETL évolue.
Au fur et à mesure que votre conception ETL est affinée, vous commencerez à développer une idée claire des champs qui seront extraits, générés, et validé à chaque étape du flux de données. Pour aider à documenter le lignage des données telles qu’elles découlent du source aux tables de l’entrepôt de données, vous pouvez créer des mappages source-cible détaillés qui informations pour les champs à chaque étape.
Un moyen courant de créer un mappage source-cible consiste à utiliser une feuille de calcul divisée en un ensemble de colonnes pour chaque étape du flux de données. Commencez par les champs de la table cible, puis travaillez en arrière pour déterminer le les champs de préparation, de zone d’atterrissage et de source requis, ainsi que les règles de validation et les doit être appliqué. L’objectif est de créer un document unique dans lequel les origines d’un champ de la table cible peuvent être retracé sur une ligne jusqu’à sa source.
À l’instar des diagrammes de flux de données de haut niveau, de nombreux professionnels de la BI ont adopté différentes variantes de source-cible
cartographie. L’organisation dans laquelle vous travaillez peut ne pas avoir de format standard pour ce type de
Documentation. Il est donc important d’utiliser un format cohérent qui est utile lors de la conception ETL et facile
à comprendre pour quiconque a besoin de dépanner ou de maintenir le système ETL à l’avenir.